Learning High-Frequency Continuous Action Chunks in Latent Space
1School of Computer Science, Shanghai Jiao Tong University
2TARS Robotics
3National University of Singapore
4Institute of Automation, Chinese Academy of Sciences
5Fudan University
*Work done during an internship at TARS Robotics. †Corresponding authors.
ICML 2026Lay Summary
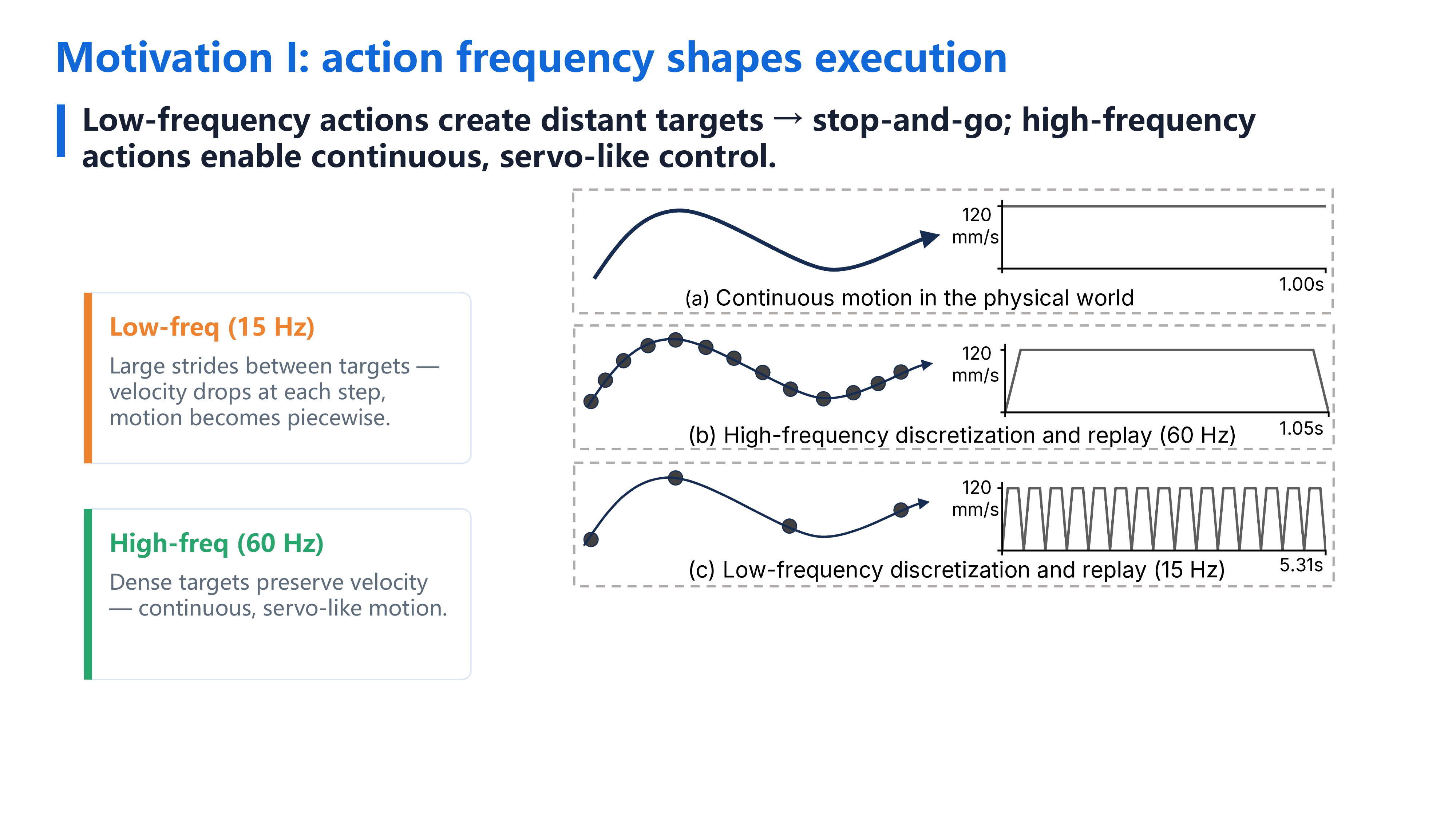
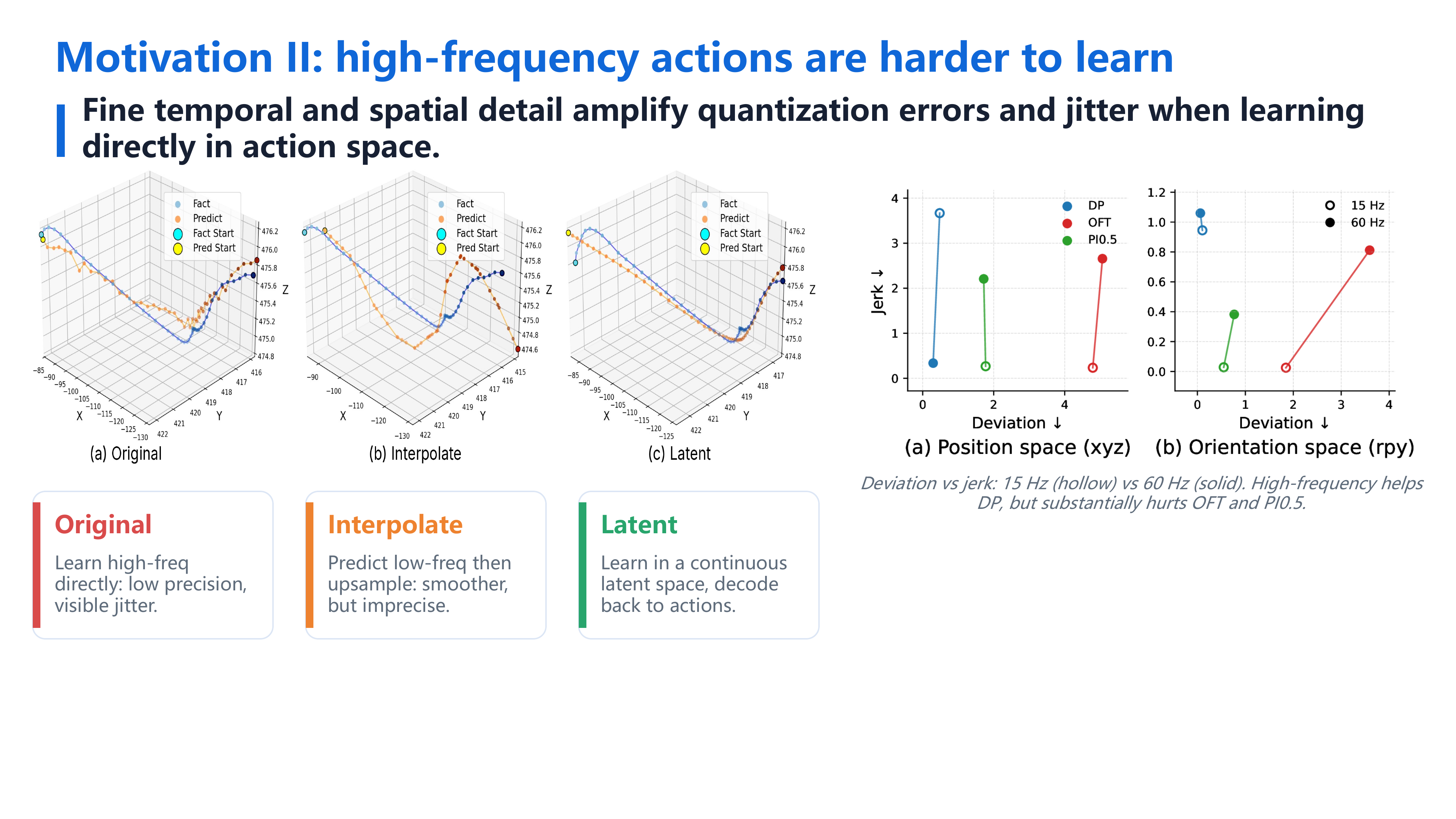
Imitation learning policies control robots by predicting short sequences of future actions, known as action chunks, and then executing these actions on the robot. Increasing the action frequency can make robot motion smoother by reducing the stop-and-go behavior often seen in low-frequency execution, allowing the robot to move with more stable velocities. However, high-frequency actions are also harder for policies to learn, because they contain denser temporal information and finer spatial variations.
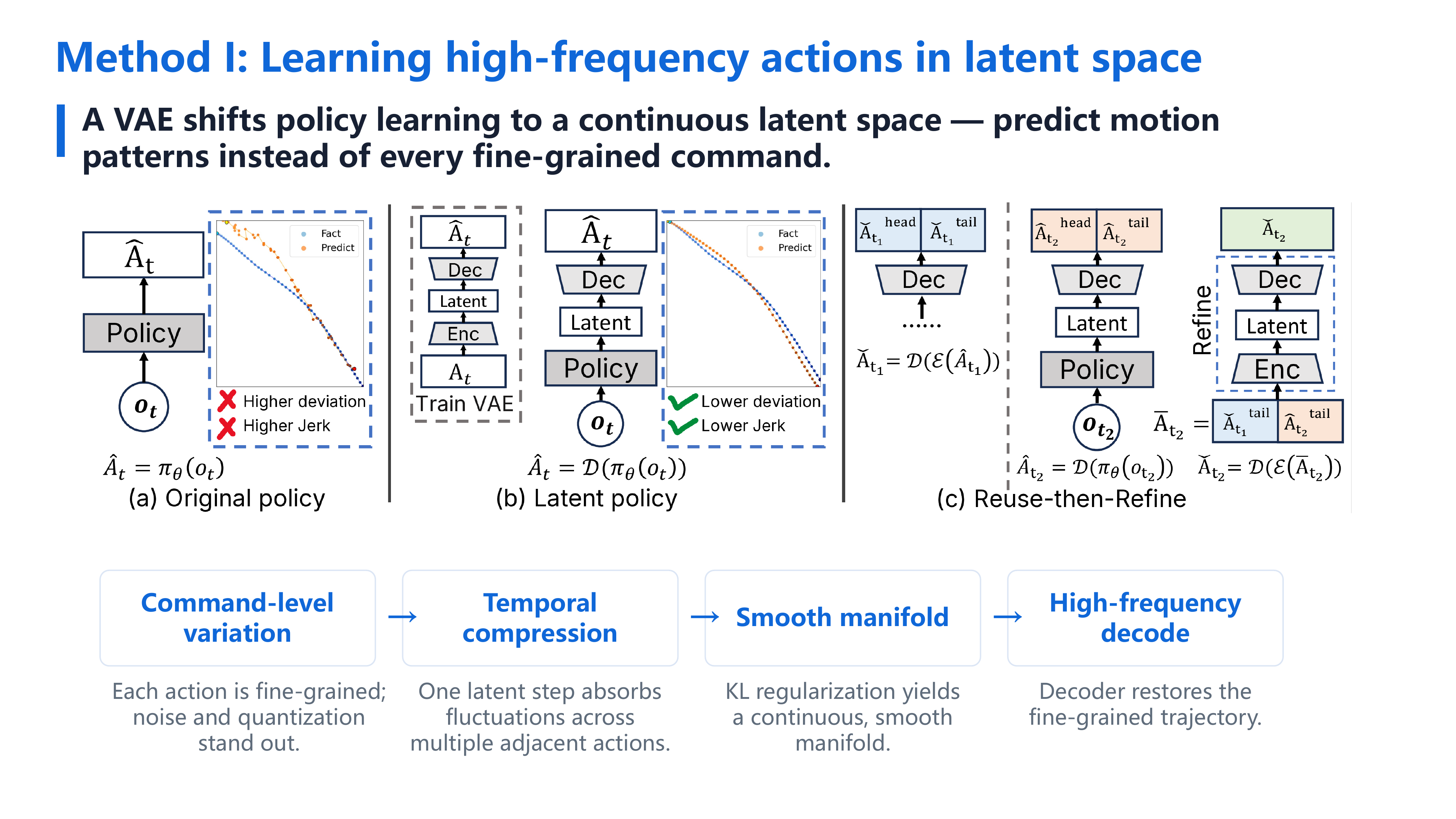
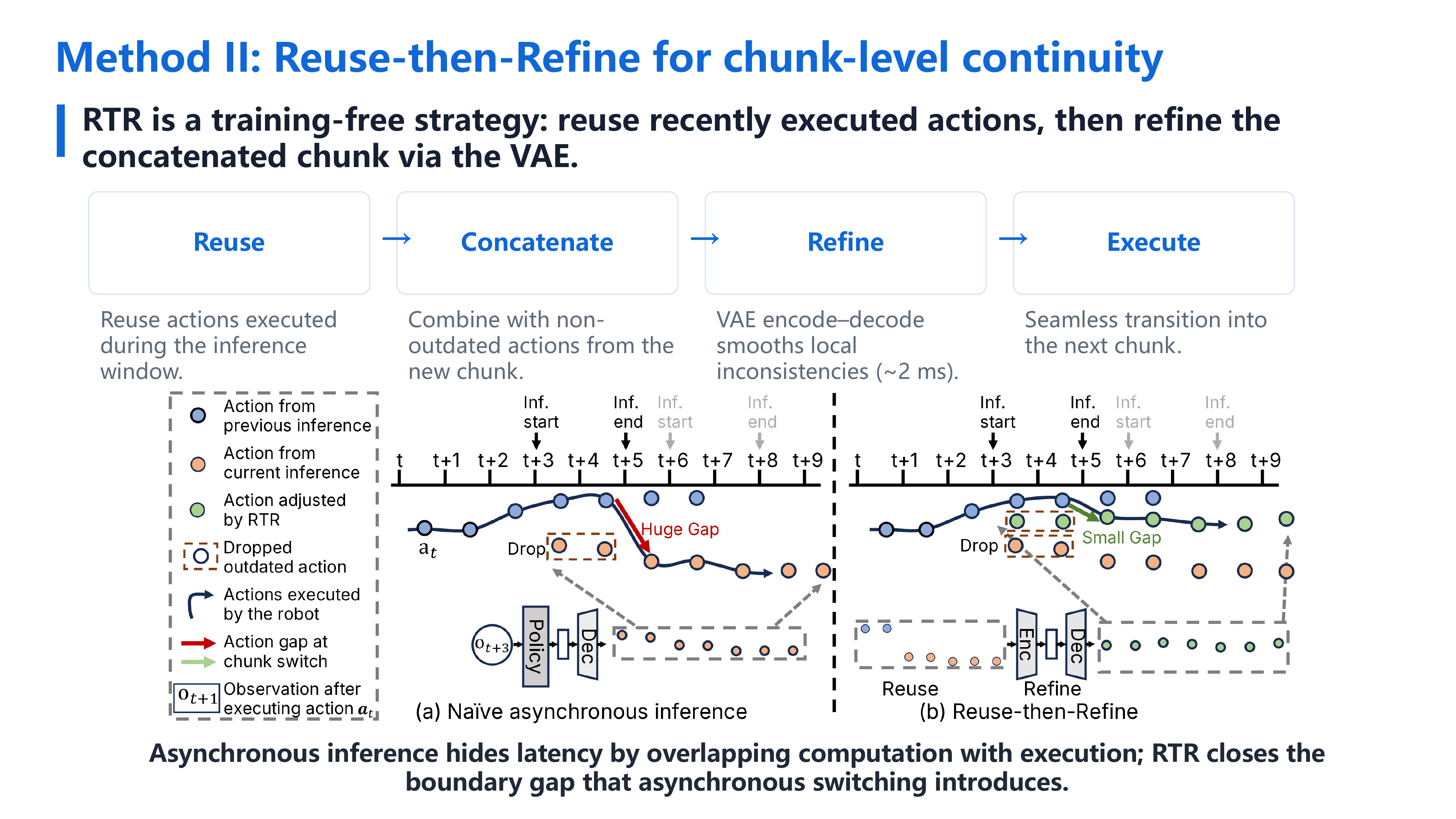
In this work, we propose learning high-frequency action chunks in a latent space, which provides a more compact and structured representation of motion. This helps the policy generate smoother and more consistent action sequences. To further reduce execution stalls caused by model inference latency, we use asynchronous inference, where the robot continues executing current actions while the policy predicts the next action chunk. However, asynchronous inference can introduce discontinuities when switching between chunks. To address this, we propose Reuse-then-Refine, a method that reduces boundary gaps between consecutive chunks and improves execution smoothness.
In real-robot experiments, our method reduces jerky motions and execution stalls across several contact-rich manipulation tasks. Overall, this work helps make learned robot policies more reliable for continuous physical interaction.
All videos are muted. Click any video to play; right-click for native browser controls. Videos play independently — pause one without affecting the others.
Latent space enables smooth high-frequency control
High-frequency actions are required for continuous robot motion with stable velocities, but learning them directly in action space is unstable. We show that learning in a continuous latent space recovers smooth, stable execution.
Motivation & Method
Before diving into the comparisons, three key ideas:
1.1 Wipe Vase (synchronous)
Continuous-contact wiping motion — smoothness directly visible in trajectory and contact quality.
DP — 4-way comparison: frequency & representation
Same task, same policy (Diffusion Policy), four action representations.
Takeaway: 15 Hz → too slow; interpolation → still jittery; direct 60 Hz → still jittery; latent 60 Hz → truly smooth.
OFT — Latent vs Original
PI0.5 — Latent vs Original
1.2 Write Board (synchronous)
Fine-motor writing task — trajectory precision and continuity are visually obvious in the handwriting output.
OFT — Latent vs Original
PI0.5 — Latent vs Original
1.3 Peel Cucumber (synchronous)
Contact-rich, force-sensitive task — stop-and-go produces visible force disturbances.
DP — 3-way high-frequency comparison
PI0.5 — Latent vs Original
Reuse-then-Refine removes chunk-boundary gaps
Latent space solves intra-chunk smoothness. Under asynchronous inference (which hides inference latency), a new problem appears: chunk-boundary discontinuities. RTR solves this with a training-free reuse-and-refine strategy. Combined latent-representation and RTR, our work achieves real-time smooth control.
Method — Reuse-then-Refine (RTR)
2.1 Wipe Vase (asynchronous)
DP — Original vs Latent vs Latent+RTR
OFT — Original vs Latent vs Latent+RTR
PI0.5 — 4-way comparison (with RT-C baseline)
RT-C is a real-time control baseline; even with RT-C, RTR still provides smoother transitions.
2.2 Write Board (asynchronous)
DP — 5-way comprehensive comparison (frequency + RTR)
The most comprehensive group: demonstrates both contributions of the paper jointly — the frequency problem and the RTR solution.
Takeaway: low-freq → interpolation → direct high-freq → latent → latent + RTR. The full evolution from stop-and-go to seamless real-time control.